Gaurav SarmaDemystifying MongoDB write operationsIn this post, we will try to understand the different factors which control the write operations in MongoDB. We will try to tie in the…5 min read·Feb 18, 2024----
Gaurav SarmaMeasuring cost of spawning GoroutinesDevelopers who learn or start with Golang are taught to treat goroutines as a very cheap version of threads. The minimum cost of spawning a…5 min read·Sep 17, 2023--1--1
Gaurav SarmaUsing Python AST to resolve dependenciesThis article covers how to resolve python dependencies using Python’s Abstract Syntax Trees (AST). There are different and maybe better…4 min read·Jun 30, 2023----
Gaurav SarmaBuilding your own Kubernetes webhookThis blog is the 2nd part of a blog post on how to write custom logic for your kubernetes objects. The first post can be found here…3 min read·Jun 2, 2023----
Gaurav SarmaKubernetes operators using KubebuilderIn this post, we will be going over the fastest no-frills approach to getting your operator off the ground using kubebuilder. The post…4 min read·May 27, 2023----
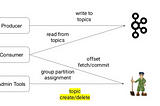
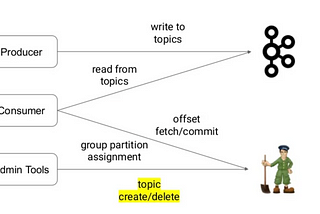
Gaurav SarmaImplement your own CDC using KafkaMost of the problems that people mention with their Kafka implementations is that they don’t have the complete visibility required over the…6 min read·Sep 18, 2022----
Gaurav SarmaMigrating Kafka topics without downtimeWhy do we need to migrate a kafka topic?3 min read·Sep 15, 2022----
Gaurav SarmaKafka, KRaft and Storage TiersI was recently looking at a managed Kafka service and came across services like AWS MSK and Kafka on Confluent Cloud. While comparing these…6 min read·May 21, 2022----
Gaurav SarmainGeek CultureUnderstanding Monarch, Google’s Planet-Scale Monitoring SystemMonarch is a planet scale in-memory time series database developed by Google. It is mainly used by as a reliable monitoring system by most…5 min read·May 20, 2021----
Gaurav SarmainGeek CultureUnderstanding the Concept of Virtual Time Using the Time Warp AlgorithmIntroduction6 min read·Apr 10, 2021----